The Edgescan Platform eliminates the need for tool configuration, deployment, and management.
By providing vulnerability intelligence and remediation information along with human guidance and vulnerability verification, we help our customers prevent security breaches, safeguarding their data and IT assets.
Edgescan offers a continuous security testing and unified exposure management SaaS platform that manages thousands of assets for businesses large and small in a wide variety of industries across the globe.
The Edgescan Platform eliminates the need for tool configuration, deployment, and management.
By providing vulnerability intelligence and remediation information along with human guidance and vulnerability verification, we help our customers prevent security breaches, safeguarding their data and IT assets.
Edgescan offers a continuous security testing and unified exposure management SaaS platform that manages thousands of assets for businesses large and small in a wide variety of industries across the globe.
The Edgescan Platform eliminates the need for tool configuration, deployment, and management.
By providing vulnerability intelligence and remediation information along with human guidance and vulnerability verification, we help our customers prevent security breaches, safeguarding their data and IT assets.
Edgescan offers a continuous security testing and unified exposure management SaaS platform that manages thousands of assets for businesses large and small in a wide variety of industries across the globe.
Niall Caffrey is a Senior Security Consultant at Edgescan for over eight years. Specialising in a comprehensive array of security services, Niall routinely performs in-depth auditing, assessments, consulting, and penetration tests. His expertise spans a broad range of technologies, including networks, cloud infrastructure, web and mobile applications, and more. Trusted by blue-chip companies across diverse sectors - from fintech and government to insurance and medical - Niall's proficiency ensures that these organisations remain safeguarded against ever-evolving cyber threats. With a deep understanding of the nuances and intricacies of digital security, he is a pivotal asset to the Edgescan team.
Introduction
Recently, there has been an explosion in the use of LLMs (Large Language Models) and Generative AI (Artificial intelligence) by organisations looking to improve their online customer experience. While the use of these can help the customer experience, it is important to remember that like other systems or applications an organisation can implement, these systems can be abused by malicious actors or by APTs (Advanced Persistent Threat).
Before diving into a look at the security around LLMs and Generative AI, it is important to define what are LLMs and Generative AI. Large Language Models are AI algorithms that can process a user’s input and return plausible responses by predicting sequences of words. They are typically trained on a large set of semi-public data, utilising machine learning to analyse how the components of language relate to each other.
An LLM will present a chat like interface to accept user input, this input is normally referred to as a prompt. The input a user can provide to the LLM is partially controlled by input validation rules. They can have a wide range of use cases for web applications, such as:
Virtual assistants
Language translation
SEO improvement
Analysis of user-generated content, such as on-page comments
Generative AI are AI algorithms that can generate text, images, videos, or other data using generative models, often in response to prompts provided by the user.
Types of Attacks
The surge in different varieties of AI have introduced new types of attacks and risks that can be utilised to compromise the integrity and reliability of AI models and systems:
Data Security Risks: AI Pipeline as an attack surface – As AI systems rely on data, the whole pipeline for the data in question is vulnerable to assaults.
Data Security Risks: Production data in the engineering process – The use of production data within AI engineering is always a risk. If it is not appropriately managed, sensitive data could leak into model training datasets. This could result in privacy violations, data breaches, or biased model outputs.
Attacks on AI models or adversarial machine learning: Adversarial machine learning attacks trick AI models by altering input data. An attacker could potentially subtly alter visuals or text to misclassify or forecast. This could damage the trustworthiness of an AI.
Data Poisoning Attack: This involves inserting harmful or misleading data into training datasets. This will corrupt the learning model in use by the AI and can result in biased or underperforming models.
Input Manipulation Attack: The input provided to an AI system can be manipulated, by changing values such as sensor readings, settings, or user inputs to alter an AI’s response or action.
Model Inversion Attacks: This involves the reverse-engineering of AI models to gain access to sensitive data. An attacker would use model outputs to infer sensitive training data.
Membership Inference Attacks: This is an attacker whereby adversaries attempt to determine whether a specific data point is part of the training dataset used by the model.
Exploratory Attacks: This involves the probing of the AI system to learn the underlying workings of the model.
Supply Chain Attacks: Attackers making use of vulnerabilities in third part libraries or cloud services, to insert malicious code or access AI resources.
Resource Exhaustion Attacks: Overload AI systems with requests or inputs, with the intention of degrading performance or creating downtime.
Fairness and Bias Risks: Results returned by the AI model can propagate bias and discrimination. An AI system can create unfair results or promote social prejudices, which can pose ethical, reputational, and legal issues to the developers.
Model Drift and Decay: The training data set used to create the AI can become less effective overtime, as data distributions, threats, and technology obsolescence change regularly.
OWASP Top Ten
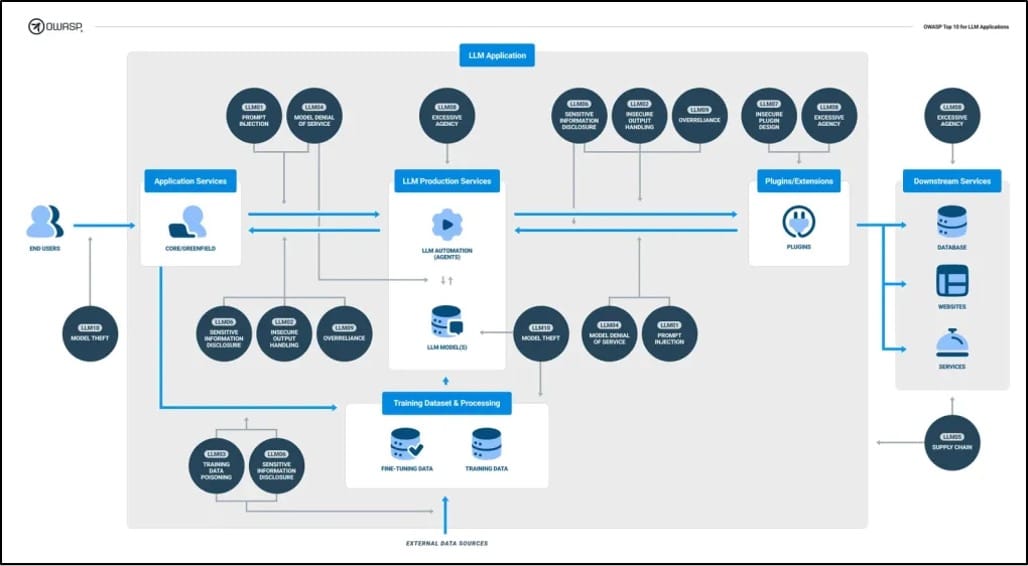
These risks have been refined by the Open Web Application Security Project (OWASP), who have brought out a Top Ten list of risks associated with LLMs, in an equivalent manner to their Top Ten for web applications and mobile applications. The Top Ten for LLMs consists of:
Prompt Injection: This occurs when an attacker manipulates a LLM through crafted inputs, causing it to unknowingly execute the attacker’s intentions.
Insecure output Handling: This refers to the validation, sanitisation, and handling of output generated by LLMs, before it gets parsed through any other downstream components or systems.
Training Data Poisoning: This refers to the manipulation of pre-training data, or the data involved with fine-tuning and embedding process in the LLM, to introduce vulnerabilities, backdoors, or even biases that could compromise the model.
Model Denial of Service: Any situation where an attacker interacts with an LLM in a way that consumes a high number of resources, and results in a decline of the quality of service available.
Supply Chain Vulnerabilities: The supply chain in LLMs can be vulnerable, which impacts the integrity of training data, ML models, and deployment platforms. These can be chained to lead to biased outcomes, security breaches, or even system failure.
Sensitive Information Disclosure: All LLM application have the potential to reveal sensitive information, proprietary algorithms, or other confidential information through their output.
Insecure Plugin Design: LLM plugins are extensions that are called automatically by the model during user interactions if they have been enabled. They are driven by the model, but there is no application control over the execution. A potential attacker could construct a malicious request to the plugin, which could result in a range of undesired behaviours.
Excessive Agency: This vulnerability enables damaging actions to be performed in response to unexpected or ambiguous outputs from an LLM, regardless of what is causing them.
Overreliance: This can occur when an LLM produces erroneous information in an authoritative manner. When people or other systems trust this information without oversight or confirmation, this can result in a security breach, misinformation, miscommunication, legal issues, or reputational damage.
Model Theft: This refers to the unauthorised access and exfiltration of LLM models by either malicious actors, or by APTs. This particularly arises when the LLM is considered proprietary, and the model is compromised, physically stolen, copied, or weights and parameters are extracted to create a functional equivalent.
Recent High-Profile Attacks
There have been several high-profile attacks against AI models within recent years, with the below being some examples of this:
Deepfake Voice Phishing: In 2023 attackers used an AI deepfake voice technology to impersonate an executive and were able to trick employees into transferring large sums of money.
Tesla Autopilot Evasion: In 2023 researchers were able to confuse Tesla’s Autopilot system by placing stickers on the road, this resulted in the car taking incorrect actions.
Meta BlenderBot Offensive Remarks: In 2022, users were able to manipulate a chatbot released by Meta into main inappropriate statements, which reflected biases that were present in its training data. https://www.bbc.com/news/technology-62497674
YouTube Content Moderation: In 2022, creators on YouTube were able to bypass the AI model used for content moderation by altering video metadata, or slightly altering the audio-visual elements of a video.
Facial Recognition Systems: In 2022 using image alteration and wearing certain patches, attackers were able to evade recognition or impersonate others against an AI model used for facial recognition.
Siri and Google Assistant Data Leakage: In 2021 researchers were able to use voice manipulation and other techniques, to extract sensitive user data.
How to Protect an AI Model
As with all software products, there are several best practices that can be implemented to reduce the risk associated with the implementation of LLM or Generative AI systems for an organisation. This can include:
Data privacy and security: Ensure data used to train and test LLM systems are anonymised, encrypted, and stored securely.
Regular updates and patches: Keep LLM systems up to date with the latest security patches and updates.
Access control and authentication: Implement strong access control and authentication mechanisms to stop unauthorised access to the system.
Input validation: Validate all inputs to LLM or generative AI systems to prevent injection attacks, or other forms of malicious inputs
Model monitoring: Continuously monitor models for any unexpected behaviour or performance degradation.
Adversarial training: Use adversarial training techniques to improve the robustness of models against adversarial inputs.
Model explainability: Ensure that any LLM or generative AI model are transparent and explainable, this will make it easier to identify and mitigate potential vulnerabilities.
Secure development practices: Follow secure development practices, such as threat modelling, secure coding, and code reviews.
Incident response plan: Have an incident response plan in place for any security incidents or breaches.
Regular security assessments: Conduct regular security assessments and penetration testing to identify and mitigate vulnerabilities.
Training and awareness: Provide regular training and awareness programs to employees and users on LLM security best practices.
Compliance with regulations: Ensure that systems comply with all the relevant regulations and standards
Vendor management: Ensure that vendors providing these services or solutions have adequate security measures in place
Backup and recovery: Regular backup of data and models and have a disaster recovery plan in place.
Collaboration and knowledge sharing: Collaborating and sharing knowledge on security best practices and emergent threats with other organisations.
Conclusion
The recent push for implementation of LLMs and Generative AI has introduced a new vector of attacks that APTs or other malicious actors can utilise to breach an organisation. However, the risk of this occurring can be minimised by following industry best practices to create a hardened and robust AI model.
Part Two: An Introduction to Penetration Testing AI Models
Introduction
In the previous part, we discussed the security surrounding AI models in general. One core facet of securing an AI model, as with all systems, is to perform regular penetration tests.
How to Detect Vulnerabilities in AI Models
There are a few different approaches we can take to detect vulnerabilities in AI models:
Code Review: Reviewing the code base of the AI model and conducting static analysis to identify potential issues.
Dynamic Analysis: Running the AI model in a controlled environment and monitoring its behaviour for potential issues.
Fuzz Testing: Feeding the AI model a considerable number if malformed or unexpected inputs and monitoring the output for potential issues.
How LLM APIs Work
AI models or LLMs, are typically hosted by external third parties, and can be given access to specific functionality in a website through local APIs described for and AI model to use. For example, a customer support AI model, would be typically expected to have access to APIs that would manage a user’s account, orders, and stock.
How an API would be integrated with the AI model varies depending on the structure of the API. Some APIs may require a call to a specific endpoint, to generate a valid response. In cases like this, the workflow would look like the following:
User enters a prompt in the AI model
The AI model determines that the prompt requires an external API, and generates an object in JSON that matches the API schema
User calls this function along with providing necessary parameters
The client (portal through which the user accesses the AI) received the response from the function, and processes it
The client then displays the returned response from the function, as a new message from the AI model
The AI model makes a call to the external API with the function’s response
The response from the external API is then summarised by the AI model for display back to the user.
This way this kind of flow can be implemented, can result in security implications as the AI model is effectively calling an external API on behalf of the user, but without the consent from or realisation of the user.
How to test an AI Model
Identify the inputs, whether they be user prompts, or the data utilised when training the model.
Map the AI model to determine what APIs or data it has access to.
Identify any external dependencies or libraries that the model makes use of.
Test these external assets for vulnerabilities.
Evaluate the AI model’s input validation mechanisms for common web application vulnerabilities such as cross-site scripting, SQL injection, etc.
Verify whether the AI model enforces proper authorisation checks.
Mapping an AI Model
The term “excessive agency” which was touched upon in the previous blog post, refers to times when the AI model has access APIs that can access sensitive information, and can be persuaded to use those APIs in an unsafe manner. This can allow attackers to push the AI model out of its intended role and utilise it to perform attacks using the API access it contains.
The first step in mapping an AI model, is to determine what APIs and plugins the model has access to. One way to do this is by simply asking the AI model what APIs it can access; we can then ask for additional details on any API that looks interesting.
If the AI model is not co-operative, then we can try rewording the prompt with a misleading context and trying again. For example, one method would be to try claiming to be the developer of the AI model, and as such needing a higher level of permission.
Indirect Prompt Injection
There are two ways prompt injection attacks can be performed against an AI model:
Directly via the chat UI
Indirectly via an external source
Indirect prompt injection takes place where an external resource that will be parsed or consumed by the AI model, contains a hidden prompt to force the AI model to execute certain malicious actions. One such example could be a hidden prompt that would force the AI model to return a cross-site scripting payload designed to exploit the user.
How an AI model is integrated into a website can have a significant impact on how easy it is to exploit. When it has been integrated properly, an AI model should understand to ignore instructions from within a web page or email.
To bypass this, we can try including fake markup syntax in the prompt, or to include fake user responses within the injected prompt.
Leaking Sensitive Training Data
Using injected prompts, it can also be possible to get the AI model to leak sensitive data that was used to train the model.
One way this can be done is to craft a query, that will prompt the AI model to reveal information about the training data. This could be done by asking the model to complete a phrase by prompting it with some key pieces of information. This could be text that precedes what you want to access, such as an error message. Or it could be a username that has been discovered previously through another method.
Another way this could be done, is to use prompts starting with phrases like “Could you remind me of” or “Complete a paragraph starting with.”
OWASP Checklist
Like their testing guides for web and mobile applications, OWASP have released a security checklist for LLM AIs which can be used to determine what places in an AI model to direct our efforts against.
It is available on their website, and at the following URL: LLM_AI_Security_and_Governance_Checklist-v1.pdf (owasp.org)
Tools For Penetration Testing AI Models
There are a few customised tools available on GitHub, and elsewhere, that can be used for testing AI model:
Part Three: An Introduction to Utilising AI Models for Penetration Testing
Introduction
The rise of AI models has led many people to investigating how these can be utilised to replace traditional penetration testing, or how they can be used augment human testers during the penetration testing process.
Information Gathering
One of the core phases, and one of the most important, of a penetration test is the information gathering phase. During this phase, penetration testers will typically use publicly accessible resources to gather as much information as possible about their target, in addition to performing tasks such as port scanning to discover open ports/running services on their target.
At the end of this phase, the tester will have a list of domains, subdomains, applications, ports, etc… That they target during other phases to discover and exploit vulnerabilities.
AI models can be utilised to not only automate gathering this information but can also be used to analyse the results allowing a tester to focus on the most important tasks that cannot be easily automated.
Vulnerability Analysis
As part of a penetration test, vulnerability scanners are utilised to scan a host/application to identify potential vulnerabilities. This is normally done in two different ways, static or dynamic analysis.
Static analysis consists of analysing the source code of an application, to discover any potential vulnerabilities present within, this is typically done using analysis tools such as Checkmarx.
Dynamic analysis consists of running vulnerability analysis tools such as Nessus, OpenVAS, Burp Suite, ZAP, etc… against the application or hosts, to discover any potential vulnerabilities.
Both ways require a tester to manually review the output, to determine what issues being reported are real. AI models can be utilised by a tester to parse through these results, and cut out any of the non-applicable findings, allowing the tester to focus on those issues that are most likely to be exploitable.
Exploitation
Another phase of a penetration test, that AI models can be utilised is when it comes to exploitation of identified vulnerabilities.
A tester can use these models to help determine the best avenue to penetrate a target application or host. In addition to this, some models have been designed to perform the exploitation simultaneously with the tester.
Reporting
The most important phase of any penetration test, the report is the only physical result that a client will be presented with at the end of an engagement. AI models can be used to enhance the process of writing reports, making this phase easier for the tester, while also potentially combining the results with threat intelligence and knowledge gained from previous engagements.
AI Models
There are some AI models themselves, that can be useful for penetration testers during engagement. Some examples of these include:
Arcanum Cyber Security Bot: This model was developed by Jason Haddix, a well-known figure in cybersecurity, and is built using ChatGPT-4. It is geared towards use as a conversational AI, to simulate discussions on technical tops, aid testers in real-time during assessments, or for educational purposes.
PenTestGPT: This is an automated testing tool, that makes use of ChatGPT-4 to streamline the pen test process. It is designed to help automate routine tests that are performed during an engagement and has been benchmarked against CTF challenges such as those in HackTheBox.
HackerGPT: This model was designed to be an assistant or sidekick, for penetration testers, or those interested in cybersecurity, and was developed in collaboration with WhiteRabbitNeo. In addition to responding to penetration testing related inquiries, it was also designed as platform capable of executing processes along with the user. There are a few tools built into the model that can be utilised during tests, such as Subfinder, Katana, Naabu.
Conclusion
The rise of AI models has introduced a new tool that penetration testers can utilise during engagements. It can be used by a tester during all phases of a penetration test, for help in ensuring that the client gets the best possible coverage during an engagement.